고정 헤더 영역
상세 컨텐츠
본문
728x90
아래 Project Structure 에 나온 순서대로 데이터 전처리를 수행한다.
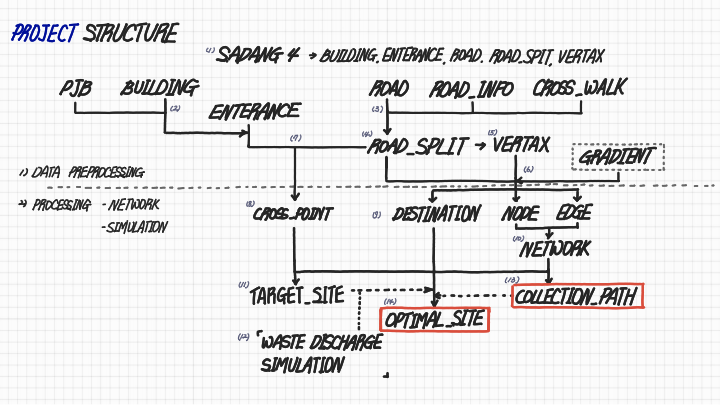
(1) 사당 4동 추출
프로젝트 대상지는 행정동 단위로 선정한다. 쓰레기 수거 업체가 행정동 단위로 선정되는 경우가 많기 때문이다. 때문에 행정동 경계 데이터 중 대상지를 추출하여 사용한다. 이번에는 사당 4동을 추출하여 사용한다.
행정동 경계를 추출한 뒤 서울시 전체 건물, 건물 출입구, 도로 데이터 중 대상지 (사당 4동) 만을 추출한다.
#%% Data Preprocessing - (1) 사당 4동
# (1) SADANG 4
sd = gpd.read_file(load_dir + '/haengjeongdong/Z_SOP_BND_ADM_DONG_PG.shp', encoding='cp949')
sd = sd[sd['ADM_DR_NM'] == '사당4동']
sd.crs # EPSG 5181
sd = sd.geometry.iloc[0]
(2) 건물 + 건축물대장
건물 데이터에 건축물대장 중 표제부 데이터를 결합한다. 건물 데이터의 geometry 데이터에 건축물대장 중 표제부 데이터를 결합하여 주용도, 기타 용도, 세대 및 가구 수 정보를 획득한다.
표제부의 PPK (관리건축물대장 PK) 는 추후 건축물의 고유 번호로서 사용될 여지가 있기 때문에 남겨둔다. 도로명주소 기준 데이터의 BPK (Building PK) 데이터는 건물 출입구 데이터와 결합에서 사용될 예정이기 때문에 역시 남겨둔다.
건축물대장에서 획득한 정보 중 주용도와 기타 용도를 활용하여 아파트와 그 부속 건물 데이터를 제거한다. 아파트의 경우 이미 거점형 쓰레기 처리 시스템을 가지고 있기 때문에 프로젝트의 대상에서 제외한다.
가구 및 세대 수는 추후 쓰레기 배출 시뮬레이션 알고리즘에 활용될 예정이다. 세대와 가구를 결합하여 POP 컬럼으로 구성한다.
#%% Data Preprocessing - (2) 건물
# (2) BUILDING + PJB
bd = gpd.read_file(load_dir + '/building/Z_KAIS_TL_SPBD_BULD_11000.shp', encoding='cp949')
bd = bd[['BUL_MAN_NO', 'SIG_CD', 'EMD_CD', 'LNBR_MNNM', 'LNBR_SLNO', 'geometry']]
bd.info()
bd.crs # EPSG 5181
bd['PNU'] = bd['SIG_CD'] + bd['EMD_CD'] + '00' + '1' + bd['LNBR_MNNM'].astype(str).str.zfill(4) + bd['LNBR_SLNO'].astype(str).str.zfill(4)
bd['BPK'] = bd['SIG_CD'].astype(str) + '-' + bd['BUL_MAN_NO'].astype(str)
bd = bd[['BPK', 'PNU', 'geometry']]
bd = bd[bd.intersects(sd)]
bd.plot()
bd = bd.reset_index(drop=True)
file_columns = pd.read_excel(load_dir + '/pjb/filecolumns.xlsx')
use_cols = ['관리_건축물대장_PK', '시군구_코드', '법정동_코드', '번', '지', '주_용도_코드_명', '기타_용도', '세대_수(세대)', '가구_수(가구)']
pjb = pd.read_csv(load_dir + '/pjb/mart_djy_03.txt', sep='|', names=file_columns['mart_djy_03(pjb)'].dropna(), header=None, usecols=use_cols, dtype=str, encoding='cp949')
pjb = pjb[pjb['시군구_코드'].str[:2] == '11']
pjb['PNU'] = pjb['시군구_코드'] + pjb['법정동_코드'] + '1' + pjb['번'] + pjb['지']
pjb = pjb[['관리_건축물대장_PK', 'PNU', '주_용도_코드_명', '기타_용도', '세대_수(세대)', '가구_수(가구)']]
pjb.columns = ['PPK', 'PNU', 'MN_CD', 'ETC_CD', 'SD', 'GG']
bd = pd.merge(bd, pjb, on=['PNU'], how='left')
bd.isna().sum()
bd = bd.fillna(0)
bd['POP'] = bd['SD'].astype(int) + bd['GG'].astype(int)
bd = bd[bd['POP'] != 0]
bd = bd.reset_index(drop=True)
apt = bd[bd['ETC_CD'].str.contains('아파트') == True]['PNU'].tolist()
for a in apt:
bd = bd[bd['PNU'] != a]
bd = bd[['PPK', 'BPK', 'PNU', 'MN_CD', 'ETC_CD', 'POP', 'geometry']]
bd.to_file(save_dir + '/sadang_building/sadang_building.shp', encoding='cp949')
del file_columns, use_cols, pjb, a, apt
(3) 도로 + 도로 정보 + 횡단보도 데이터
도로 중심선 데이터에 상세 정보와 횡단보도 데이터를 결합하여 도로 별 도로폭과 횡단보도 포함 여부를 획득한다. 두 정보 모두 쓰레기 처리 거점 시설 설치 여부 판단에 사용된다.
# (3) ROAD + ROAD_INFO + CROSS_WALK
road = gpd.read_file(load_dir + '/road/Z_KAIS_TL_SPRD_MANAGE_11000.shp', encoding='cp949')
road = road[['RN', 'geometry']]
road.columns = ['RNM', 'geometry']
road.crs # EPSG 5181
road = road[road.intersects(sd)]
road.plot()
road = road.reset_index(drop=True)
road_info = pd.read_csv(load_dir + '/road/서울시 도로노선 정보.csv', encoding='cp949')
road_info = road_info[['노선명(도로명)', '도로규모']]
road_info.columns = ['RNM', 'RD_SC']
road = pd.merge(road, road_info, on=['RNM'], how='left')
road = road[['RNM', 'RD_SC', 'geometry']]
road.duplicated().sum()
cross_walk = gpd.read_file(load_dir + '/seoul_cross walk/A004_A.shp', encoding='cp949')
cross_walk = cross_walk[['geometry']]
cross_walk = cross_walk.to_crs(epsg=5181) # EPSG 5186 > 5181
road = gpd.sjoin(road, cross_walk, how='left')
road = road.reset_index().drop_duplicates(subset=['index']).fillna(-1)
road['index_right'] = road['index_right'].apply(lambda x : 1 if x != -1 else 0)
road.columns = ['index', 'RNM', 'RD_SC', 'geometry', 'CR_TF']
road = road[['RNM', 'RD_SC', 'CR_TF', 'geometry']]
road.to_file(save_dir + '/sadang_road/sadang_road.shp', encoding='cp949')
del road_info
(4) ~ (5) 도로 데이터 분해
도로 중심선 데이터를 분해하여 최소단위로 분해한 ROAD_SPLIT 데이터와 VERTAX 데이터를 획득한다. 해당 데이터들은 추후 Network 알고리즘에서 Node 와 Edge로 사용될 예정이다.
도로 데이터에 결합한 도로 폭 데이터는 '도시ㆍ군계획시설의 결정ㆍ구조 및 설치기준에 관한 규칙' 상 규모 별 분류 기준을 따른다. 추후 데이터 처리의 편의를 위해 Label Encoder 를 이용하여 해당 데이터를 숫자로 바꿔준다.
# (4) ROAD_SPLIT
road = gpd.read_file(save_dir + '/sadang_road/sadang_road.shp', encoding='cp949')
road_spt = {'RNM':[], 'RNB':[], 'RD_SC':[], 'CR_TF':[], 'geometry':[]}
for idx, r in tqdm(enumerate(road['geometry']), leave=True):
vtx = r.coords
for v in range(len(vtx) - 1):
road_spt['RNM'].append(road['RNM'][idx])
road_spt['RNB'].append(v)
road_spt['RD_SC'].append(road['RD_SC'][idx])
road_spt['CR_TF'].append(road['CR_TF'][idx])
road_spt['geometry'].append(LineString([vtx[v], vtx[v+1]]))
road_spt = gpd.GeoDataFrame(road_spt, geometry='geometry', crs="EPSG:5181")
road_spt = road_spt[road_spt.intersects(sd)]
road_spt = road_spt.reset_index(drop=True)
road_spt.to_file(save_dir + '/sadang_road/sadang_road_split.shp', encoding='cp949')
del idx, r, vtx, v
# (5)~(6) Vertax
road_spt = gpd.read_file(save_dir + '/sadang_road/sadang_road_split.shp', encoding='cp949')
vertax = {'geometry':[]}
for r in road_spt['geometry']:
vertax['geometry'].append(r.coords[0])
vertax['geometry'].append(r.coords[1])
vertax = pd.DataFrame(vertax)
del r
vertax['TP'] = 0 # Vertax Type : (0 : 일반) / (1 : 교차점) / (2 : Destinaion)
vertax['TP'][vertax.duplicated(subset=['geometry'], keep=False)] = 1
vertax = vertax.drop_duplicates(['geometry']).reset_index(drop=True)
vertax['geometry'] = vertax['geometry'].apply(lambda x : Point(x))
vertax['NN'] = vertax.index
vertax = vertax[['NN', 'TP', 'geometry']]
vertax = gpd.GeoDataFrame(vertax, geometry='geometry' , crs="EPSG:5181")
road_scale = ['소로', '소로1류', '소로2류', '소로3류',
'중로1류', '중로2류', '중로3류',
'대로1류', '대로2류', '대로3류',
'광로1류', '광로2류', '광로3류']
encoder = LabelEncoder()
encoder.fit(road_scale)
road_spt['RD_SC'] = encoder.transform(road_spt['RD_SC'])VERTAX 별 속성에 따른 타입을 부여한다.
- 일반 : 0
- 교차점 : 1
- 거점 설치 가능 도로 교차점 : 2
Type 2 는 폭이 소로 2류 이상이고 횡단보도가 지나지 않는 도로의 양 끝 점 중 교차점에 해당하는 VERTAX 가 해당한다.
destination = {'geometry':[]}
for d in tqdm(road_spt[(road_spt['RD_SC'] >= 9) & (road_spt['CR_TF'] == 0)]['geometry'], leave=True):
d = d.coords
for i in range(len(d)):
destination['geometry'].append(d[i])
destination = pd.DataFrame(destination)
destination = destination.drop_duplicates(['geometry']).reset_index(drop=True)
destination['geometry'] = destination['geometry'].apply(lambda x : Point(x))
destination = gpd.GeoDataFrame(destination, geometry='geometry', crs="EPSG:5181")
vertax = gpd.sjoin(vertax, destination, how='left')
vertax['TP'][(vertax['TP'] == 1) & (vertax['index_right'].isna() == False)] = 2
vertax.to_file(save_dir + '/sadang_road/sadang_vertax.shp', encoding='cp949')
del road_scale, encoder, destination, d, i, vertax['index_right']
* (6) 도로 + 경사도
도로에 경사도를 추가하여 Network 알고리즘 상의 가중치로 활용할 예정이었으나 아직 적용하지 못 함.
(7) 건물 + 건물 출입구 데이터
앞서 서술했듯, 도로명주소 기준 데이터의 BPK 를 기준으로 결합한다. 출입구는 건물 내부 사람이 어느 도로 방향으로 출입하는지 판단하기 위해 사용된다.
# (10) ENTERANCE + BUILDING
enter = gpd.read_file(load_dir + '/building/Z_KAIS_TL_SPBD_ENTRC_11000.shp', encoding='cp949')
enter = enter[['SIG_CD', 'BUL_MAN_NO', 'ENT_MAN_NO', 'geometry']]
enter.info()
enter.crs # EPSG 5181
enter['BPK'] = enter['SIG_CD'] + '-' + enter['BUL_MAN_NO'].astype(str)
enter = enter[['BPK', 'ENT_MAN_NO', 'geometry']]
enter = enter[enter.intersects(sd)]
enter.plot()
enter = enter.reset_index(drop=True)
col_nm = list(enter.columns)
enter = pd.merge(enter, bd, on=['BPK'], how='inner')
enter = enter.iloc[:, :len(col_nm)]
enter.columns = col_nm
enter = enter.drop_duplicates().reset_index(drop=True)
enter.to_file(save_dir + '/sadang_building/sadang_enterance.shp', encoding='cp949')
del col_nm개 중에는 매칭된 출입구 데이터가 없는 건물들이 있다. 해당 건물들의 경우 따로 출입구 데이터를 만들어줘야 한다. 출입구 생성 알고리즘의 Pseudo code 는 다음과 같다.
- 건물 Polygon 을 LineString 단위로 분해한다.
- 그 중 건물과 가장 가까운 도로와 가장 가까운 것을 찾는다.
- 해당 LineString 의 중심점을 출입구로 지정한다.
위 과정을 통해 출입구 데이터가 누락된 건물들에도 출입구 데이터를 생성해준다.
no_enter = pd.DataFrame(set(bd['BPK'].tolist()) - set(enter['BPK'].tolist())) # Enterance 생성 (Enterance Data 누락된 경우)
no_enter.columns = ['BPK']
no_enter = pd.merge(no_enter, bd, on=['BPK'], how='left')
no_enter = no_enter[['BPK', 'geometry']]
no_enter = no_enter.drop_duplicates().reset_index(drop=True)
no_enter = gpd.GeoDataFrame(no_enter, geometry='geometry', crs="EPSG:5181")
no_enter = gpd.sjoin_nearest(no_enter, road_spt, how = 'left')
no_enter = no_enter[['BPK', 'RNM', 'geometry']]
no_enter['geometry'] = no_enter.boundary
road_unary = road_spt.unary_union
new_enter = []
for e in tqdm(no_enter['geometry'], leave=True):
point = []
distance = []
for p in range(len(e.xy[0]) - 1):
point.append(Point(e.xy[0][p], e.xy[1][p]))
for p in point:
distance.append(p.distance(road_unary))
distance = np.array(distance)
new_enter.append(Point( (point[np.where(distance == np.sort(distance)[0])[0][0]].x + point[np.where(distance == np.sort(distance)[1])[0][0]].x)/2
,(point[np.where(distance == np.sort(distance)[0])[0][0]].y + point[np.where(distance == np.sort(distance)[1])[0][0]].y)/2 ))
no_enter['geometry'] = new_enter
no_enter = no_enter.reset_index().rename(columns={'index':'ENT_MAN_NO'})
no_enter['ENT_MAN_NO'] = 'no_ent' + ' ' + no_enter['ENT_MAN_NO'].astype(str)
no_enter = no_enter[['BPK', 'ENT_MAN_NO', 'geometry']]
enter = pd.concat([enter, no_enter])
enter = enter.reset_index(drop=True)
enter.to_file(save_dir + '/sadang_building/sadang_enterance.shp', encoding='cp949')
del no_enter, road_unary, new_enter, e, p, point, distance
이렇게 데이터 전처리 과정이 마무리되었다. 이제 전처리가 완료된 데이터를 가공하여 원하는 결과물을 얻기 위한 알고리즘을 적용시킨다.
다음은 코드 전문이다.
#%% Library
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point, LineString
from sklearn.preprocessing import LabelEncoder
import os
import warnings
from tqdm import tqdm
#%% Setting & Directory
os.chdir(r'C:\Users\PC\Desktop\주영준\진행중인 프로젝트\PROJECT_NEW POINT\002 Source Code')
warnings.simplefilter("ignore")
load_dir = (r'C:\Users\PC\Desktop\주영준\진행중인 프로젝트\PROJECT_NEW POINT\001 Load Directory')
save_dir = (r'C:\Users\PC\Desktop\주영준\진행중인 프로젝트\PROJECT_NEW POINT\003 Save Directory')
#%% Data Preprocessing - (1) 사당 4동
# (1) SADANG 4
sd = gpd.read_file(load_dir + '/haengjeongdong/Z_SOP_BND_ADM_DONG_PG.shp', encoding='cp949')
sd = sd[sd['ADM_DR_NM'] == '사당4동']
sd.crs # EPSG 5181
sd = sd.geometry.iloc[0]
#%% Data Preprocessing - (2) 건물
# (2) BUILDING + PJB
bd = gpd.read_file(load_dir + '/building/Z_KAIS_TL_SPBD_BULD_11000.shp', encoding='cp949')
bd = bd[['BUL_MAN_NO', 'SIG_CD', 'EMD_CD', 'LNBR_MNNM', 'LNBR_SLNO', 'geometry']]
bd.info()
bd.crs # EPSG 5181
bd['PNU'] = bd['SIG_CD'] + bd['EMD_CD'] + '00' + '1' + bd['LNBR_MNNM'].astype(str).str.zfill(4) + bd['LNBR_SLNO'].astype(str).str.zfill(4)
bd['BPK'] = bd['SIG_CD'].astype(str) + '-' + bd['BUL_MAN_NO'].astype(str)
bd = bd[['BPK', 'PNU', 'geometry']]
bd = bd[bd.intersects(sd)]
bd.plot()
bd = bd.reset_index(drop=True)
file_columns = pd.read_excel(load_dir + '/pjb/filecolumns.xlsx')
use_cols = ['관리_건축물대장_PK', '시군구_코드', '법정동_코드', '번', '지', '주_용도_코드_명', '기타_용도', '세대_수(세대)', '가구_수(가구)']
pjb = pd.read_csv(load_dir + '/pjb/mart_djy_03.txt', sep='|', names=file_columns['mart_djy_03(pjb)'].dropna(), header=None, usecols=use_cols, dtype=str, encoding='cp949')
pjb = pjb[pjb['시군구_코드'].str[:2] == '11']
pjb['PNU'] = pjb['시군구_코드'] + pjb['법정동_코드'] + '1' + pjb['번'] + pjb['지']
pjb = pjb[['관리_건축물대장_PK', 'PNU', '주_용도_코드_명', '기타_용도', '세대_수(세대)', '가구_수(가구)']]
pjb.columns = ['PPK', 'PNU', 'MN_CD', 'ETC_CD', 'SD', 'GG']
bd = pd.merge(bd, pjb, on=['PNU'], how='left')
bd.isna().sum()
bd = bd.fillna(0)
bd['POP'] = bd['SD'].astype(int) + bd['GG'].astype(int)
bd = bd[bd['POP'] != 0]
bd = bd.reset_index(drop=True)
apt = bd[bd['ETC_CD'].str.contains('아파트') == True]['PNU'].tolist()
for a in apt:
bd = bd[bd['PNU'] != a]
bd = bd[['PPK', 'BPK', 'PNU', 'MN_CD', 'ETC_CD', 'POP', 'geometry']]
bd.to_file(save_dir + '/sadang_building/sadang_building.shp', encoding='cp949')
del file_columns, use_cols, pjb, a, apt
#%% Data Preprocessing - (3) ~ (6) 도로
# (3) ROAD + ROAD_INFO + CROSS_WALK
road = gpd.read_file(load_dir + '/road/Z_KAIS_TL_SPRD_MANAGE_11000.shp', encoding='cp949')
road = road[['RN', 'geometry']]
road.columns = ['RNM', 'geometry']
road.crs # EPSG 5181
road = road[road.intersects(sd)]
road.plot()
road = road.reset_index(drop=True)
road_info = pd.read_csv(load_dir + '/road/서울시 도로노선 정보.csv', encoding='cp949')
road_info = road_info[['노선명(도로명)', '도로규모']]
road_info.columns = ['RNM', 'RD_SC']
road = pd.merge(road, road_info, on=['RNM'], how='left')
road = road[['RNM', 'RD_SC', 'geometry']]
road.duplicated().sum()
cross_walk = gpd.read_file(load_dir + '/seoul_cross walk/A004_A.shp', encoding='cp949')
cross_walk = cross_walk[['geometry']]
cross_walk = cross_walk.to_crs(epsg=5181) # EPSG 5186 > 5181
road = gpd.sjoin(road, cross_walk, how='left')
road = road.reset_index().drop_duplicates(subset=['index']).fillna(-1)
road['index_right'] = road['index_right'].apply(lambda x : 1 if x != -1 else 0)
road.columns = ['index', 'RNM', 'RD_SC', 'geometry', 'CR_TF']
road = road[['RNM', 'RD_SC', 'CR_TF', 'geometry']]
road.to_file(save_dir + '/sadang_road/sadang_road.shp', encoding='cp949')
del road_info
# (4) ROAD_SPLIT
road = gpd.read_file(save_dir + '/sadang_road/sadang_road.shp', encoding='cp949')
road_spt = {'RNM':[], 'RNB':[], 'RD_SC':[], 'CR_TF':[], 'geometry':[]}
for idx, r in tqdm(enumerate(road['geometry']), leave=True):
vtx = r.coords
for v in range(len(vtx) - 1):
road_spt['RNM'].append(road['RNM'][idx])
road_spt['RNB'].append(v)
road_spt['RD_SC'].append(road['RD_SC'][idx])
road_spt['CR_TF'].append(road['CR_TF'][idx])
road_spt['geometry'].append(LineString([vtx[v], vtx[v+1]]))
road_spt = gpd.GeoDataFrame(road_spt, geometry='geometry', crs="EPSG:5181")
road_spt = road_spt[road_spt.intersects(sd)]
road_spt = road_spt.reset_index(drop=True)
road_spt.to_file(save_dir + '/sadang_road/sadang_road_split.shp', encoding='cp949')
del idx, r, vtx, v
# (5)~(6) Vertax
road_spt = gpd.read_file(save_dir + '/sadang_road/sadang_road_split.shp', encoding='cp949')
vertax = {'geometry':[]}
for r in road_spt['geometry']:
vertax['geometry'].append(r.coords[0])
vertax['geometry'].append(r.coords[1])
vertax = pd.DataFrame(vertax)
del r
vertax['TP'] = 0 # Vertax Type : (0 : 일반) / (1 : 교차점) / (2 : Destinaion)
vertax['TP'][vertax.duplicated(subset=['geometry'], keep=False)] = 1
vertax = vertax.drop_duplicates(['geometry']).reset_index(drop=True)
vertax['geometry'] = vertax['geometry'].apply(lambda x : Point(x))
vertax['NN'] = vertax.index
vertax = vertax[['NN', 'TP', 'geometry']]
vertax = gpd.GeoDataFrame(vertax, geometry='geometry' , crs="EPSG:5181")
road_scale = ['소로', '소로1류', '소로2류', '소로3류',
'중로1류', '중로2류', '중로3류',
'대로1류', '대로2류', '대로3류',
'광로1류', '광로2류', '광로3류']
encoder = LabelEncoder()
encoder.fit(road_scale)
road_spt['RD_SC'] = encoder.transform(road_spt['RD_SC'])
destination = {'geometry':[]}
for d in tqdm(road_spt[(road_spt['RD_SC'] >= 9) & (road_spt['CR_TF'] == 0)]['geometry'], leave=True):
d = d.coords
for i in range(len(d)):
destination['geometry'].append(d[i])
destination = pd.DataFrame(destination)
destination = destination.drop_duplicates(['geometry']).reset_index(drop=True)
destination['geometry'] = destination['geometry'].apply(lambda x : Point(x))
destination = gpd.GeoDataFrame(destination, geometry='geometry', crs="EPSG:5181")
vertax = gpd.sjoin(vertax, destination, how='left')
vertax['TP'][(vertax['TP'] == 1) & (vertax['index_right'].isna() == False)] = 2
vertax.to_file(save_dir + '/sadang_road/sadang_vertax.shp', encoding='cp949')
del road_scale, encoder, destination, d, i, vertax['index_right']
#%% Data Preprocessing - (7) 출입구
bd = gpd.read_file(save_dir + '/sadang_building/sadang_building.shp', encoding='cp949')
road_spt = gpd.read_file(save_dir + '/sadang_road/sadang_road_split.shp', encoding='cp949')
# (10) ENTERANCE + BUILDING
enter = gpd.read_file(load_dir + '/building/Z_KAIS_TL_SPBD_ENTRC_11000.shp', encoding='cp949')
enter = enter[['SIG_CD', 'BUL_MAN_NO', 'ENT_MAN_NO', 'geometry']]
enter.info()
enter.crs # EPSG 5181
enter['BPK'] = enter['SIG_CD'] + '-' + enter['BUL_MAN_NO'].astype(str)
enter = enter[['BPK', 'ENT_MAN_NO', 'geometry']]
enter = enter[enter.intersects(sd)]
enter.plot()
enter = enter.reset_index(drop=True)
col_nm = list(enter.columns)
enter = pd.merge(enter, bd, on=['BPK'], how='inner')
enter = enter.iloc[:, :len(col_nm)]
enter.columns = col_nm
enter = enter.drop_duplicates().reset_index(drop=True)
enter.to_file(save_dir + '/sadang_building/sadang_enterance.shp', encoding='cp949')
del col_nm
no_enter = pd.DataFrame(set(bd['BPK'].tolist()) - set(enter['BPK'].tolist())) # Enterance 생성 (Enterance Data 누락된 경우)
no_enter.columns = ['BPK']
no_enter = pd.merge(no_enter, bd, on=['BPK'], how='left')
no_enter = no_enter[['BPK', 'geometry']]
no_enter = no_enter.drop_duplicates().reset_index(drop=True)
no_enter = gpd.GeoDataFrame(no_enter, geometry='geometry', crs="EPSG:5181")
no_enter = gpd.sjoin_nearest(no_enter, road_spt, how = 'left')
no_enter = no_enter[['BPK', 'RNM', 'geometry']]
no_enter['geometry'] = no_enter.boundary
road_unary = road_spt.unary_union
new_enter = []
for e in tqdm(no_enter['geometry'], leave=True):
point = []
distance = []
for p in range(len(e.xy[0]) - 1):
point.append(Point(e.xy[0][p], e.xy[1][p]))
for p in point:
distance.append(p.distance(road_unary))
distance = np.array(distance)
new_enter.append(Point( (point[np.where(distance == np.sort(distance)[0])[0][0]].x + point[np.where(distance == np.sort(distance)[1])[0][0]].x)/2
,(point[np.where(distance == np.sort(distance)[0])[0][0]].y + point[np.where(distance == np.sort(distance)[1])[0][0]].y)/2 ))
no_enter['geometry'] = new_enter
no_enter = no_enter.reset_index().rename(columns={'index':'ENT_MAN_NO'})
no_enter['ENT_MAN_NO'] = 'no_ent' + ' ' + no_enter['ENT_MAN_NO'].astype(str)
no_enter = no_enter[['BPK', 'ENT_MAN_NO', 'geometry']]
enter = pd.concat([enter, no_enter])
enter = enter.reset_index(drop=True)
enter.to_file(save_dir + '/sadang_building/sadang_enterance.shp', encoding='cp949')
del no_enter, road_unary, new_enter, e, p, point, distance
2023.02.19 - [Algorithm] - [Algorithm] New Point 쓰레기 처리 시스템 구축 알고리즘 (1) Project Structure
'Algorithm' 카테고리의 다른 글
| [Algorithm] New Point 쓰레기 처리 시스템 구축 알고리즘 (1) Project Structure (0) | 2023.02.19 |
|---|---|
| [Algorithm] 쓰레기 배출 시뮬레이션 (2) (2) | 2023.01.09 |
| [Algorithm] 쓰레기 배출 시뮬레이션 (1) (0) | 2023.01.09 |
| [Algorithm] 도시화과정 시뮬레이션 (0) | 2023.01.02 |
| [Algorithm] 클러스터링 심화_이미지 처리 1 (2) (0) | 2022.12.25 |




